集群主机信息
主机名
IP
角色
部署组件
dev-vm1
192.168.1.127
master
etcd、kube-apiserver、kube-controller-manage、kube-scheduller、kubelet、kube-proxy、kubectl、kubeadmin、calico、haproxy
dev-vm2
192.168.1.249
master
etcd、kube-apiserver、kube-controller-manage、kube-scheduller、kubelet、kube-proxy、kubectl、kubeadmin、calico
dev-vm3
192.168.1.125
master
etcd、kube-apiserver、kube-controller-manage、kube-scheduller、kubelet、kube-proxy、kubectl、kubeadmin、calico
初始化系统 允许iptables检查桥接流量 确保 br_netfilter 模块被加载。通过运行lsmod | grep br_netfilter来检查模块是否加载。若要加载该模块,可执行sudo modprobe br_netfilter。配置net.bridge.bridge-nf-call-iptables变量为1,如下过程:
1 2 3 4 5 6 7 8 9 [root@dev-vm1 ~]# lsmod | grep br_netfilter [root@dev-vm1 ~]# modprobe br_netfilter [root@dev-vm1 ~]# lsmod | grep br_netfilter br_netfilter 22256 0 bridge 151336 2 br_netfilter,ebtable_broute [root@dev-vm1 ~]# sysctl -w net.bridge.bridge-nf-call-iptables=1 net.bridge.bridge-nf-call-iptables = 1 [root@dev-vm1 ~]# sysctl -w net.bridge.bridge-nf-call-ip6tables=1 net.bridge.bridge-nf-call-ip6tables = 1
配置内核参数系统重启后仍生效:
1 2 3 4 5 6 7 8 9 10 11 12 13 cat> /etc/modules-load.d/k8s.conf << EOF br_netfilter ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack_ipv4 EOF cat >> /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-iptables=1 net.bridge.bridge-nf-call-ip6tables=1 EOF
禁用交换分区(swap) 1 2 3 4 5 #关闭swap [root@dev-vm1 ~]# swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab cat >> /etc/sysctl.d/k8s.conf << EOF vm.swappiness=0 EOF
禁用SELinux和关闭防火墙 1 2 3 [root@dev-vm1 ~]# setenforce 0 [root@dev-vm1 ~]# sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config [root@dev-vm1 ~]# systemctl disable firewalld && systemctl stop firewalld
在所有主机上设置hosts解释 1 2 3 4 5 6 [root@dev-vm1 ~]# vi /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.127 dev-vm1 192.168.1.249 dev-vm2 192.168.1.125 dev-vm3
配置kubernetes安装yum源 1 2 3 4 5 6 7 8 9 10 cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
执行以下命令刷新yum源:
1 2 3 [root@dev-vm1 ~]# yum clean all [root@dev-vm1 ~]# yum makecache [root@dev-vm1 ~]# yum repolist
安装docker 删除系统中旧版本docker(如果有) 1 2 3 4 5 6 7 8 sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-engine
配置docker安装yum源 1 2 3 sudo yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo
安装最新版docker 1 2 3 4 5 [root@dev-vm1 ~]# yum install -y yum-utils device-mapper-persistent-data lvm2 [root@dev-vm1 ~]# sudo yum install docker-ce docker-ce-cli containerd.io # 启动docker服务 [root@dev-vm1 ~]# systemctl daemon-reload && systemctl enable docker && systemctl start docker
配置Docker守护程序,使用systemd来管理容器的cgroup 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 sudo mkdir /etc/docker cat <<EOF | sudo tee /etc/docker/daemon.json { "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2" } EOF # 重启docker服务 sudo systemctl enable docker sudo systemctl daemon-reload sudo systemctl restart docker
安装kubeadmin 1 2 3 [root@dev-vm1 ~]# yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes #开启kubelet开机启动 [root@dev-vm1 ~]# systemctl enable --now kubelet
docker方式配置haproxy 新建/etc/haproxy/目录作为haproxy配置文件映射目录,配置文件内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 global daemon #以守护进程的方式工作于后台,其等同于“-D”选项的功能 nbproc 1 log 127.0.0.1 local2 #通过local2进行log记录 pidfile /var/run/haproxy.pid maxconn 5000 #最大并发连接数,等同于命令行选项“-n” default=4000 defaults mode http #mode{tcp/http/health}: tcp在第四层, http在第七层. retries 3 #3次连接失败就认为服务器不可用,通过check进行检查 option redispatch #serverId对应的服务器挂掉后,强制定向到其他健康的服务器 option abortonclose maxconn 4096 timeout connect 5000ms timeout client 30000ms timeout server 30000ms timeout check 2000 log global #监控页面配置 listen admin_stats stats enable bind 0.0.0.0:8080 #监听端口 mode http option httplog maxconn 5 stats refresh 30s #30s刷新一次页面 stats uri /moniter #虚拟路径 stats hide-version #隐藏HAProxy的版本号 stats realm Global\ statistics stats auth admin:admin123456 #登录账号:密码 #配置完毕后可以通过 http://ip:8080/moniter同时输入账号密码来访问HAProxy的监控页面 listen test bind 0.0.0.0:7443 log 127.0.0.1 local0 debug balance roundrobin #负载均衡算法 mode tcp server dev-vm1 192.168.1.127:6443 check port 6443 inter 2 rise 1 fall 2 maxconn 300 server dev-vm2 192.168.1.249:6443 check port 6443 inter 2 rise 1 fall 2 maxconn 300 server dev-vm3 192.168.1.125:6443 check port 6443 inter 2 rise 1 fall 2 maxconn 300
haproxy容器启动命令如下:
1 2 3 docker run -dit --restart=always --name k8s-haproxy \ -v /etc/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro \ --network host haproxy:2.3
初始化第一个master节点 使用如下命令可以列出安装所需组件镜像
1 2 3 4 5 6 7 8 [root@dev-test01 ~]# kubeadm config images list k8s.gcr.io/kube-apiserver:v1.22.0 k8s.gcr.io/kube-controller-manager:v1.22.0 k8s.gcr.io/kube-scheduler:v1.22.0 k8s.gcr.io/kube-proxy:v1.22.0 k8s.gcr.io/pause:3.5 k8s.gcr.io/etcd:3.5.0-0 k8s.gcr.io/coredns/coredns:v1.8.4
在dev-vm1上运行如下命令:
1 kubeadm init --control-plane-endpoint "192.168.1.181:6443" --upload-certs --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.96.0.0/12
说明:
--control-plane-endpoint 标志应该被设置成负载均衡器的地址或 DNS 和端口。--upload-certs 标志用来将在所有控制平面实例之间的共享证书上传到集群。--image-repository 由于国内无法google镜像仓库,使用此参数设置为阿里的镜像仓库。由于在阿里镜像仓库里没registry.aliyuncs.com/google_containers/coredns/coredns:v1.8.4,所以需要先下载registry.aliyuncs.com/google_containers/coredns:latest然后再打上相应tag。
--apiserver-advertise-address可用于为控制平面节点的API server设置广播地址,--control-plane-endpoint可用于为所有控制平面节点设置共享端点。1 docker tag registry.aliyuncs.com/google_containers/coredns:latest registry.aliyuncs.com/google_containers/coredns:v1.8.4
命令输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 192.168.1.181:6443 --token 63wy1b.x3rls1juhbll8wgw \ --discovery-token-ca-cert-hash sha256:e72693bfb1f30f27c64445d215722a2773d17af649ac00528cd2d3d4ae687e4a \ --control-plane --certificate-key 6b3d9ffcbdd14880fa8c1481035519775c6853fb69730a0d9bacf159342f2fc2 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.1.181:6443 --token 63wy1b.x3rls1juhbll8wgw \ --discovery-token-ca-cert-hash sha256:e72693bfb1f30f27c64445d215722a2773d17af649ac00528cd2d3d4ae687e4a
说明:
将此输出复制到文本文件。 稍后其它master节点和工作节点加入集群时需要使用.
当--upload-certs与kubeadm init一起使用时,master的证书被加密并上传到kubeadm-certs Secret 中。
要重新上传证书并生成新的解密密钥,请在已加入集群节点的控制平面上使用以下命令:kubeadm init phase upload-certs --upload-certs
还可以在init期间指定自定义的–certificate-key,以后可以由 join 使用。要生成这样的密钥,可以使用命令kubeadm certs certificate-key。
将上面生成的admin.conf移到用户主目录下:
1 2 3 mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config
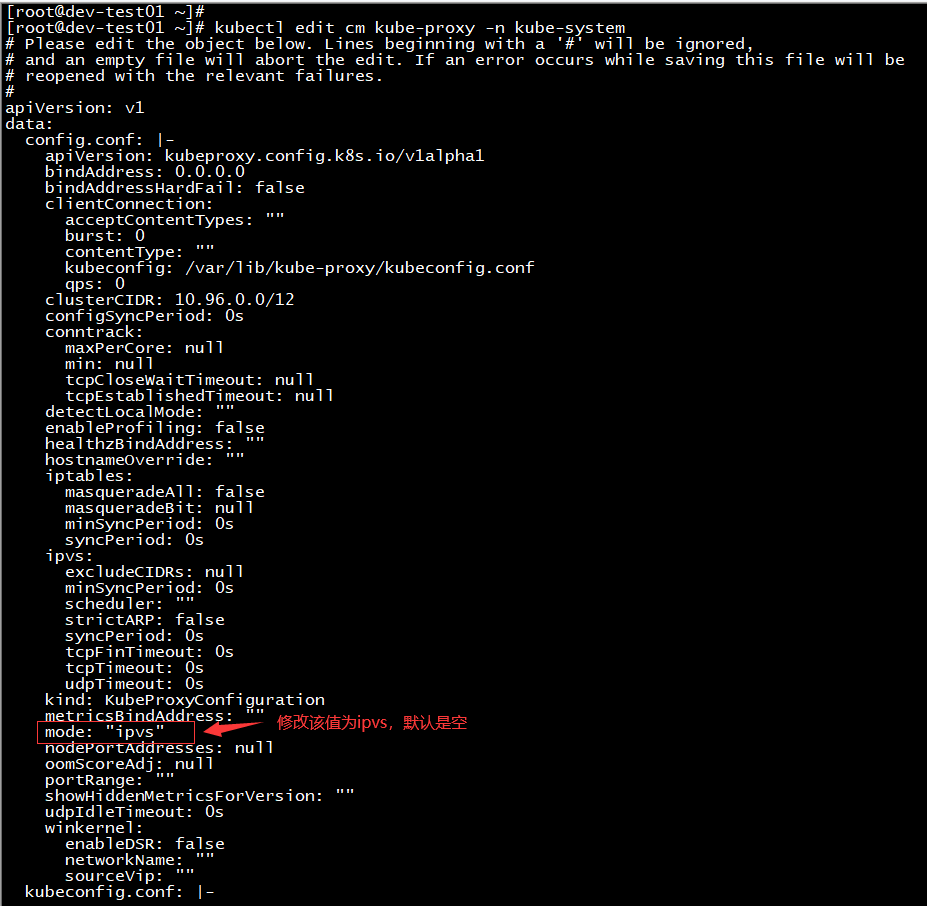
配置kube-proxy基于ipvs网络模式 修改kube-proxy的启动配置,将mode值修改为”ipvs”,默认这个值是空。如下:
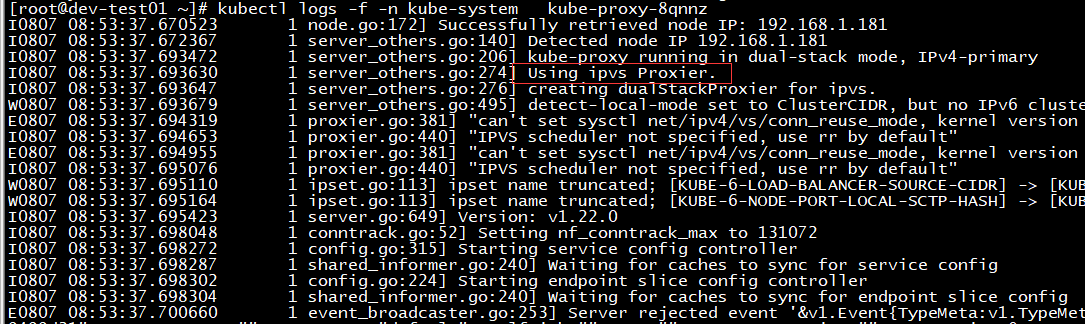
Using ipvs Proxier表明kube-proxy成功设置为ipvs模式,如下图:
安装网络插件calico 网络插件选择calico
配置网络管理 创建配置文件/etc/NetworkManager/conf.d/calico.conf以防止NetworkManager干扰接口,内容如下:
1 2 3 4 cat> /etc/NetworkManager/conf.d/calico.conf << EOF [keyfile] unmanaged-devices=interface-name:cali*;interface-name:tunl*;interface-name:vxlan.calico EOF
下载calico安装calico.yaml 1 [root@dev-vm1 ~]# curl https://docs.projectcalico.org/manifests/calico.yaml -O
修改calico.yaml文件 calico.yaml默认pods cidr为192.168.0.0/16并且是注释掉的,因此修改为10.96.0.0/12并去掉注释。
1 [root@dev-vm1 ~]# sed -i -e "s?192.168.0.0/16?10.96.0.0/12?g" calico.yaml
修改后如下:
1 2 - name: CALICO_IPV4POOL_CIDR value: "10.96.0.0/12"
1 [root@dev-vm1 ~]# kubectl apply -f calico.yaml
复制第一台master上证书到另外两台master相应目录中 1 2 3 4 5 6 7 8 备注:操作前分别在两台master主机上创建相应目录mkdir -p /etc/kubernetes/pki/etcd/ [root@dev-vm1 ~]# cd /etc/kubernetes/pki/ [root@dev-vm1 pki]# scp ca.* sa.* front-proxy-ca.* 192.168.1.249:/etc/kubernetes/pki/ [root@dev-vm1 pki]# scp ca.* sa.* front-proxy-ca.* 192.168.1.125:/etc/kubernetes/pki/ [root@dev-vm1 pki]# scp etcd/ca.* 192.168.1.249:/etc/kubernetes/pki/etcd/ [root@dev-vm1 pki]# scp etcd/ca.* 192.168.1.125:/etc/kubernetes/pki/etcd/ [root@dev-vm1 pki]# scp /etc/kubernetes/admin.conf 192.168.1.249:/etc/kubernetes/ [root@dev-vm1 pki]# scp /etc/kubernetes/admin.conf 192.168.1.125:/etc/kubernetes/
将其它master加入集群 在需要加入集群的节点上运行下列命令:
1 2 [root@dev-vm2 ~]# docker pull registry.aliyuncs.com/google_containers/coredns:latestt [root@dev-vm2 ~]# docker tag registry.aliyuncs.com/google_containers/coredns:latest registry.aliyuncs.com/google_containers/coredns:v1.8.4
在运行加入集群命令前需要在节点上创建/etc/cni/net.d目录,如下命令:
1 2 3 4 [root@dev-vm2 ~]# mkdir -p /etc/cni/net.d kubeadm join 192.168.1.181:6443 --token 63wy1b.x3rls1juhbll8wgw \ --discovery-token-ca-cert-hash sha256:e72693bfb1f30f27c64445d215722a2773d17af649ac00528cd2d3d4ae687e4a \ --control-plane --certificate-key 6b3d9ffcbdd14880fa8c1481035519775c6853fb69730a0d9bacf159342f2fc2
安装Dashbord 下载dashbord部署yaml文件 1 [root@dev-test01 ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
说明:由于某些原因国内是无法直接下载这个文件
部署dashbord 应用上一步下载的yaml文件即可,如下:
1 [root@dev-test01 ~]# kubectl apply -f recommended.yaml
创建dashbord UI管理用户帐号 新建dashboard-adminuser.yaml文件,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard
应用dashboard-adminuser.yaml文件创建帐号:
1 [root@dev-test01 ~]# kubectl apply -f dashboard-adminuser.yaml
获取访问Bearer token 1 2 3 kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}" eyJhbGciOiJSUzI1NiIsImtpZCI6IkNVSms5MFVwdGxEOHlYc0g1TmlTVWJsOUtHblQtT0s0TDlFcDdmTFBTMkEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLTZ0ZG02Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzODg5NDk0ZC1jMjU2LTQwYmItODBiMS00YmE5NjRkNTg4NzQiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.EzTxAMBgCcJ7HWn28NFBj58teXPjdak2ef-nkqIk7sdBej5TYzkOr_oGkVifEb2ZHsXiMdoGAKH7wO4a4m5K628ghLOPVy1Q8GKGWfvdZqTnqt9ALnmVoFgPnfnnWU3IEENQXwKEpfwJrnRB16-CoGep_rqhFAhGd5o7Y0dxw495FH-hEU8qRNWJr9ZzCcRVf03zG2_fO7zoW9xrCKvL-iZHjGCMbv2hif8zYlJTUpKen0kWa-rElJ7eEF3eJSjq0PwtUtPna9-Z-98CqyuTYs5UDJt7_JJ--Dg16ybQEA-e8bKLnzeEGNdJ4ddppO0UJUCn926ohoA12ElIJKqmOw
部署Kubernetes Metrics Server Metrics Server 是 Kubernetes 内置自动缩放管道的可扩展、高效的容器资源指标来源。
下载Metrics server部署yaml文件 1 wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
说明:由于某些原因国内是无法直接下载这个文件
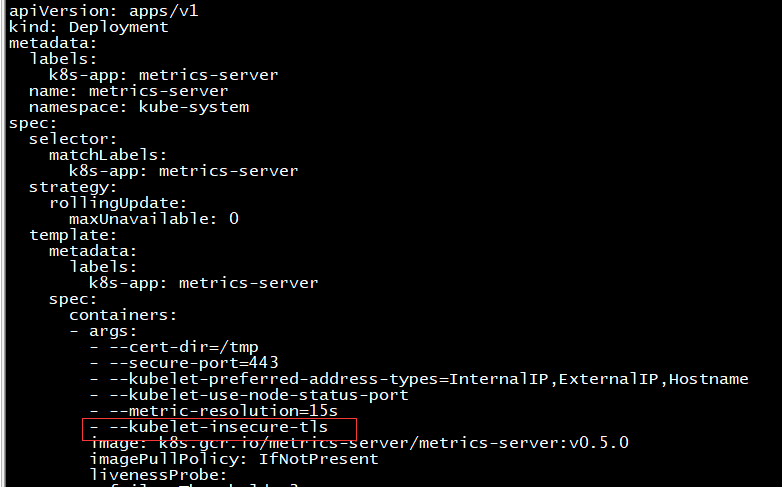
修改components.yaml文件,并应用部署 在components.yaml文件中的Deployment部分的容器参数中添加--kubelet-insecure-tls参数关闭证书验证
使用外部etcd集群配置高可用k8s集群 配置高可用etcd集群 配置etcd高可用集群参考etcd的相关文档,这里不在描述。
复制etcd访问的tls证书 从etcd集群中的任何etcd节点复制下列证书到第一个master节点:
1 2 3 /etc/kubernetes/pki/etcd/ca.crt /etc/kubernetes/pki/apiserver-etcd-client.crt /etc/kubernetes/pki/apiserver-etcd-client.key
设置kubeadmin配置文件 创建一个名为 kubeadm-config.yaml的文件内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration kubernetesVersion: stable controlPlaneEndpoint: "LOAD_BALANCER_DNS:LOAD_BALANCER_PORT" #apiserver负载均衡器ip和端口 imageRepository: "registry.aliyuncs.com/google_containers" etcd: external: endpoints: - https://ETCD_0_IP:2379 - https://ETCD_1_IP:2379 - https://ETCD_2_IP:2379 caFile: /etc/kubernetes/pki/etcd/ca.crt certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
初始化集群第一个master节点 初始化master、应用网络插件、其它master节点加入集群等的步骤都与使用内部etcd时的初始化一样,运行如下命令:
1 kubeadm init --config kubeadm-config.yaml --upload-certs
安装过程出现问题 coreDNS状态不正常 1 2 3 4 5 6 7 [root@dev-vm1 ~]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-78d6f96c7b-t2xnr 1/1 Running 0 22m kube-system calico-node-4t2pb 1/1 Running 0 22m kube-system coredns-545d6fc579-5rqjz 0/1 Running 0 28m kube-system coredns-545d6fc579-gztfz 0/1 Running 0 28m kube-system etcd-dev-vm1 1/1 Running 0 28m
查看pod日志报如下错误:
1 2 3 4 [INFO] plugin/ready: Still waiting on: "kubernetes" [INFO] plugin/ready: Still waiting on: "kubernetes" E0607 08:24:21.215568 1 reflector.go:138] pkg/mod/k8s.io/client-go@v0.21.1/tools/cache/reflector.go:167: Failed to watch *v1.EndpointSlice: failed to list *v1.EndpointSlice: endpointslices.discovery.k8s.io is forbidden: User "system:serviceaccount:kube-system:coredns" cannot list resource "endpointslices" in API group "discovery.k8s.io" at the cluster scope [INFO] plugin/ready: Still waiting on: "kubernetes"
由日志信息可看出是权限问题。 system:coredns的权限范围,添加下面部分
1 2 3 4 5 6 7 8 [root@dev-vm1 ~]# kubectl edit clusterrole system:coredns - apiGroups: - discovery.k8s.io resources: - endpointslices verbs: - list - watch
查看集群核心组件状态时,scheduler和controller-manager异常 使用kubectl get componentstatus输出状态如下:
1 2 3 4 5 6 [root@dev-vm1 ~]# kubectl get componentstatus Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused etcd-0 Healthy {"health":"true"}
出现这个问题的原因是/etc/kubernetes/manifests/下的kube-controller-manager.yaml和kube-scheduler.yaml中启动参数设置的默认端口是0。 --port 0参数注释掉,然后重启kubelet服务即可。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@dev-vm1 ~]# vi /etc/kubernetes/manifests/kube-controller-manager.yaml apiVersion: v1 kind: Pod .... spec: containers: - command: - kube-controller-manager - --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf - --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf - --bind-address=127.0.0.1 - --client-ca-file=/etc/kubernetes/pki/ca.crt - --cluster-name=kubernetes - --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt - --cluster-signing-key-file=/etc/kubernetes/pki/ca.key - --controllers=*,bootstrapsigner,tokencleaner - --kubeconfig=/etc/kubernetes/controller-manager.conf - --leader-elect=true # - --port=0 #注释掉这一行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@dev-vm1 ~]# vi /etc/kubernetes/manifests/kube-scheduler.yaml apiVersion: v1 kind: Pod ... spec: containers: - command: - kube-scheduler - --authentication-kubeconfig=/etc/kubernetes/scheduler.conf - --authorization-kubeconfig=/etc/kubernetes/scheduler.conf - --bind-address=127.0.0.1 - --kubeconfig=/etc/kubernetes/scheduler.conf - --leader-elect=true # - --port=0 #注释掉这一行
kubelet报异常日志 使用systemctl status kubelet -l查看服务状态时报如下异常日志:
1 2 3 4 5 6 7 Jun 07 22:07:02 dev-vm3 kubelet[43654]: I0607 22:07:02.184088 43654 container_manager_linux.go:995] "CPUAccounting not enabled for process" pid=43654 Jun 07 22:07:02 dev-vm3 kubelet[43654]: I0607 22:07:02.184098 43654 container_manager_linux.go:998] "MemoryAccounting not enabled for process" pid=43654 Jun 07 22:07:03 dev-vm3 kubelet[43654]: E0607 22:07:03.870531 43654 summary_sys_containers.go:47] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to get container info for \"/system.slice/kubelet.service\": unknown container \"/system.slice/kubelet.service\"" containerName="/system.slice/kubelet.service" Jun 07 22:07:03 dev-vm3 kubelet[43654]: E0607 22:07:03.870594 43654 summary_sys_containers.go:47] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/docker.service\": failed to get container info for \"/system.slice/docker.service\": unknown container \"/system.slice/docker.service\"" containerName="/system.slice/docker.service" Jun 07 22:07:13 dev-vm3 kubelet[43654]: E0607 22:07:13.959837 43654 summary_sys_containers.go:47] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to get container info for \"/system.slice/kubelet.service\": unknown container \"/system.slice/kubelet.service\"" containerName="/system.slice/kubelet.service" Jun 07 22:07:13 dev-vm3 kubelet[43654]: E0607 22:07:13.959873 43654 summary_sys_containers.go:47] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/docker.service\": failed to get container info for \"/system.slice/docker.service\": unknown container \"/system.slice/docker.service\"" containerName="/system.slice/docker.service" Jun 07 22:07:24 dev-vm3 kubelet[43654]: E0607 22:07:24.068455 43654 summary_sys_containers.go:47] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to get container info for \"/system.slice/kubelet.service\": unknown container \"/system.slice/kubelet.service\"" containerName="/system.slice/kubelet.service"
原因是在CentOS系统上,kubelet启动时,会执行节点资源统计,需要systemd中需要开启对应的选项,如果不设置,kubelet是无法执行该统计命令,导致 kubelet一直报上面的错误信息。
1 2 3 4 [root@dev-vm3 ~]# vi /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf [Service] CPUAccounting=true MemoryAccounting=true